Overview
Every year, the US Food and Drug Administration (FDA) receives a large number of medical device reports, many of which cause serious injury or death. When considering what specific devices were creating the most reports, continuous glucose monitors (CGM) were the second most reported. CGMs are an important device when it comes to tracking blood glucose levels in diabetic patients. In order to ensure patients are safe while using CGMs, these devices must work properly and device malfunctions must be identified. Due to the number of reports the FDA receives it is tough to physically consider every report.
Through the use of unsupervised learning, key topics can be extracted from the entire database of reports. This will allow each report to be classified based on an overarching topic which can drastically speed up the human review process.
Data
Data Collection
The entire database for this analysis can be here. The text data was collected by the FDA through the device report form. Data was only used for the years 2016 to 2021 and only considered Dexcom CGM devices (G4, G5, and G6). This resulted in a dataset containing 15,780,419 device reports relating to the Dexcom CGM. This dataset was then loaded into python using pandas.
Data Cleaning
After some exploration of the dataset, there are two categories of reports. One contains information about the original problem or event and the second contains updates to this original report case. Only the original report cases will be considered.
From external research, it was also determined the Dexcom G4 and Dexcom G5 devices were discontinued by the end of 2020. We will only consider G6 devices assuming updates to the older models are not taking place anymore.
Preprocessing
A large part of topic modeling is ensuring the data is properly preprocessed. The following steps outline the preprocessing process taken for this analysis.
Unify Strings
We can use regular expressions to remove any characters that are not in A-Z, a-z, or 0-9. These characters do not provide any value when extracting topics. All text will be converted to lowercase to provide similarly across all reports.
Tokenize
Next, tokenization can be used to break every word down into its own string. This step is important so the model’s output will be a group of words for each topic.
Stop Words
Next, because we tokenized to words, stop words must be removed. The general ‘English’ stopwords that are provided in the NLTK package were used. This list was also extended to add more stopwords that were frequently appearing in the dataset but did not provide much value.
Lemmatization
Next, the WordNetLemmatizer() from the NLTK package, was used to lemmatize each token. Lemmatization was chosen over stemming to help when interpreting topics.
Term Frequency - Inverse Document Frequency (TF-IDF)
The final preprocessing step is creating a term-document matrix. TF-IDF will convert text into frequencies representing how relevant certain words are in the device reports. This will provide a numeric summary which is what is needed for topic modeling. TfidVectorizer() from the scikit-learn package can be used to create the TF-IDF vector.
Topic Modeling
For topic modeling, two techniques will be explored and the results will be evaluated based on the interpretability of the results (extracted topics). Due to limited computational power provided for this project, the max number of topics explored will be 10.
Non-Negative Matrix Factorization (NMF)
NMF is a linear algebra-based, dimensionality reduction technique that will split the document-term matrix into a document-topic matrix and a topic-term matrix. Latent Semantic Analysis (LSA) was also explored but provided similar results to NMF. Because NMF produced strictly positive results it was chosen over LSA.
Extracted Topics
After exploring 2-10 topics, 3 appeared to give the most distinct and interpretable topics. The following table shows the top 10 most common words in each of the 3 topics:
| Topic Number | Top 10 Words |
|---|---|
| Topic 1 | ‘reported’, ’transmitter’, ‘failed’, ’error’, ‘data’, ‘injury’, ‘intervention’, ‘medical’, ‘allegation’, ‘occurred’ |
| Topic 2 | ’loss’, ‘signal’, ‘performed’, ‘one’, ‘hour’, ‘within’, ‘window’, ‘share’, ‘investigation’, ’log’ |
| Topic 3 | ‘reading’, ‘glucose’, ‘bg’, ‘meter’, ’event’, ‘customer’, ‘patient’, ‘additional’, ‘information’, ‘available’ |
Example Case
Now consider how the first report case is classified.
| Document (Report Case) 1 - Preprocessed |
|---|
| dexcom made aware inaccuracy continuous glucose monitor blood glucose meter sensor inserted hip data provided evaluation complaint confirmation probable cause could not determined labeling indicates patient use belly abdomen patient year old choose upper buttock look place belly upper buttock padding sensor not tested approved site talk hcp best site additional event patient information available |
Result
| Topic Number | Result |
|---|---|
| Topic 1 | 0.002 |
| Topic 2 | 0.000 |
| Topic 3 | 0.028 |
From the results, the most similar topic to the first report case is topic 3. From our topics and result, NMF appears to be a good technique that is rather computationally inexpensive.
Latent Dirichlet Allocation (LDA)
A more computationally expensive technique can be used to possibly improve topic coherence.
In simple terms, LDA considers:
- Documents are made up of a mix of topics. For each document, a probability will be assigned to each topic.
- Topics are made up of a mix of words. Words can overlap between different topics.
Result
Because LDA is an iterative algorithm, due to the limited computational power for this project, LDA could not be explored to its full potential. Topics were extracted for 2 and 3 topics. This problem could be solved in the future by possibly fitting LDA in chunks.
Post Topic Analysis
From the topics extracted using NMF, the table below will define what each topic’s theme is.
| Topic Number | Overall Theme |
|---|---|
| Topic 1 | Reports relating to the device’s transmitter |
| Topic 2 | Reports relating to the device’s signal (loss) |
| Topic 3 | Reports relating to the device’s glucose readings |
After all device report cases are given a topic the following plots can provide insight into when certain issues came about.
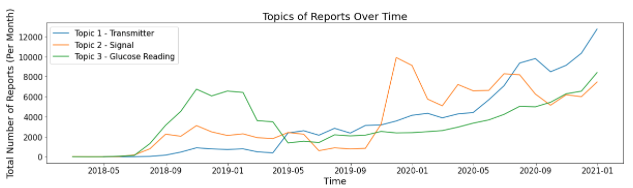
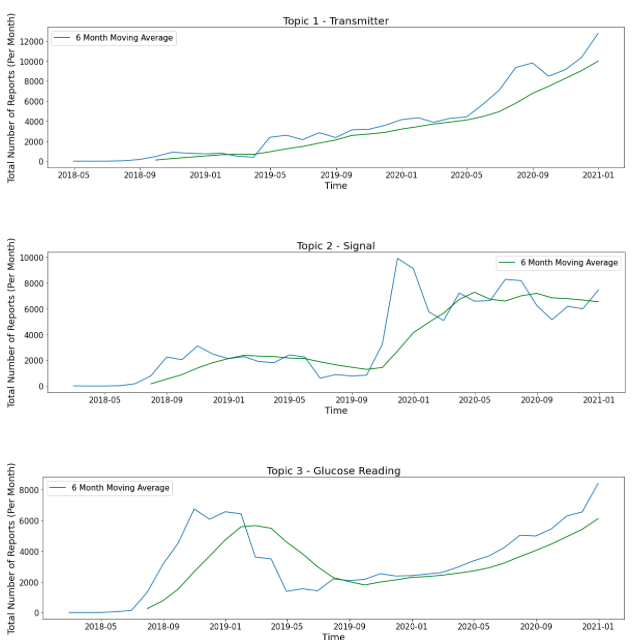
When considering reports involving glucose readings, we see a large increase in the first year the G6 device was released. This increase dropped back to the moving average and followed a stable uptrend. This could provide evidence that early in the G6’s lifetime, there were issues with readings but this issue was solved. When considering reports involving issues with signals, we see a large increase after about 18 months of release. After this increase, the trend seems to remain flat. This explanation for this change in means is unknown and could be explored in future studies. When considering reports involving transmitters, we see a constant increase in trend since G6’s release. Around July 2019, transmitters overtake signals to become the most occurring issue. Since this date, the difference between transmitter issues and other issues has been increasing. Because of this, issues with transmitters need to be addressed in the future.